Parsing CSV with automatic data type identification
Introduction
Most CSV parsers used today provide no help with identifying the data type of a field. The data types commonly used in CSV range from string, integer, floating point and dates. When working with CSV data, it is important not to lose type information by parsing everything as string.
While asking the user to pick a type for each field is a workable solution, it tends to get tedious for the user especially if there are a large number of fields.
Pre-Parsing Rows
One approach which can be taken to identify types is to parse the first row (after the header) row and determine the type based on that. This can however result in wrong type information since not all fields in the first row may be populated. Also it is possible that rows further down may be of a different type. What is to be done in these cases?
The approach taken by Argon is to pre-parse first 100 rows and attempt to identify the type of each field. By using the first 100 rows, we ensure that fields the empty-value problem (stated above) is handled. Also, if the types were to change due to parsing of successive rows, the type is set to string since no other type is general enough.
Automatically identifying types
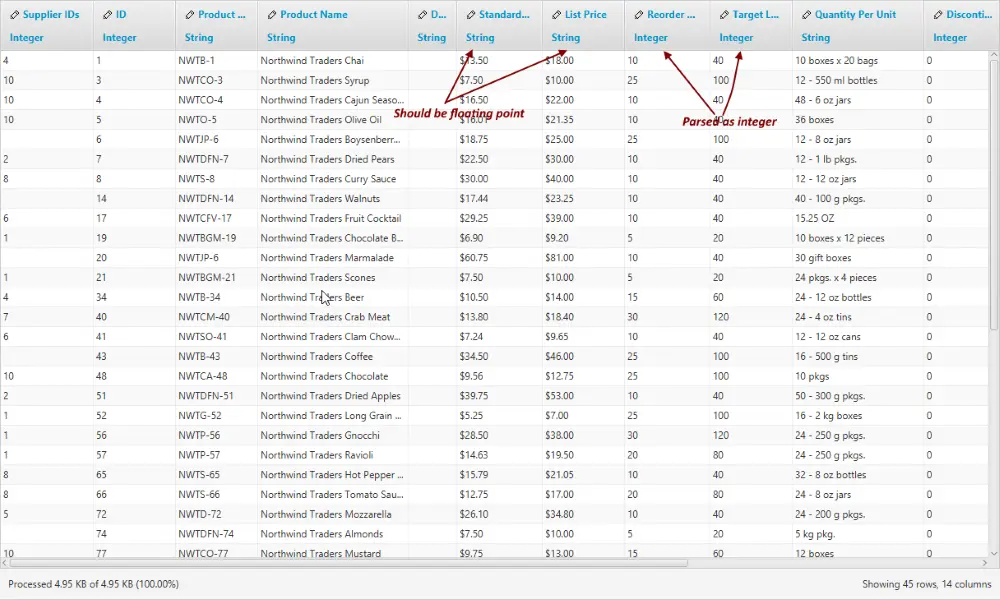
The following image shows a few fields which have been automatically identified as integers. However, some fields which include a currency symbol should be marked as numbers and the currency field removed. At this point, the type can be manually adjusted and extra junk removed.
Adjusting types manually
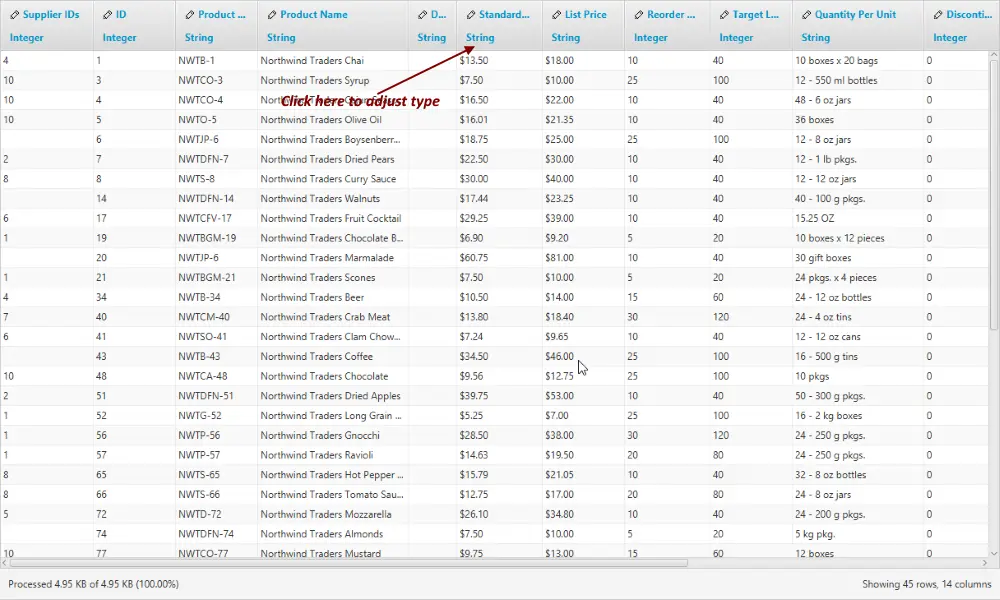
For those fields whose type does not match, you can adjust type manually as shown below.
1. Click on the type name to display the type dialog.
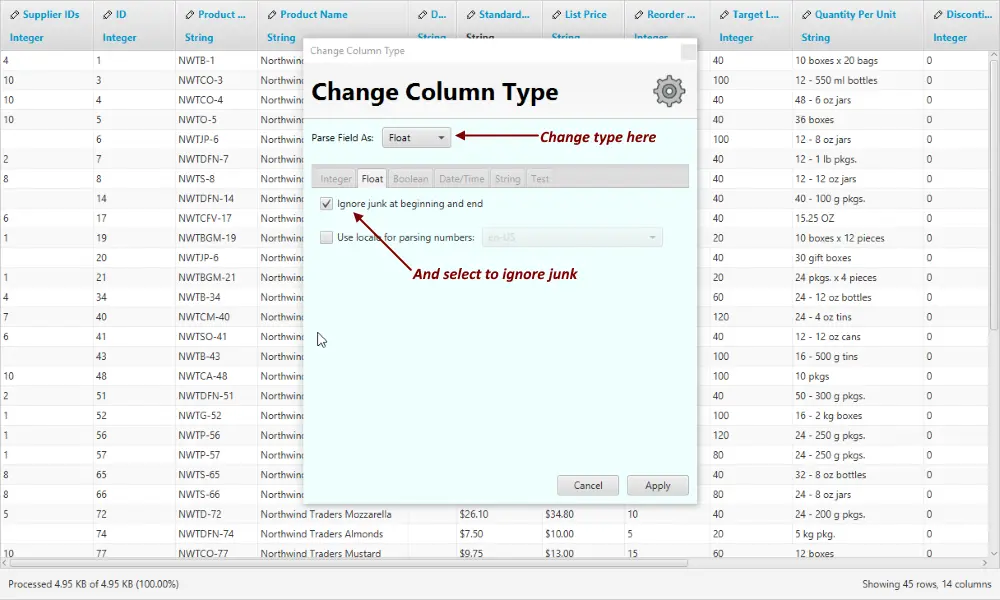
2. Change type in the type dialog to Float
Also select the checkbox to ignore non-numeric characters at the beginning and the end (to get rid of the currency sign). Click Apply.
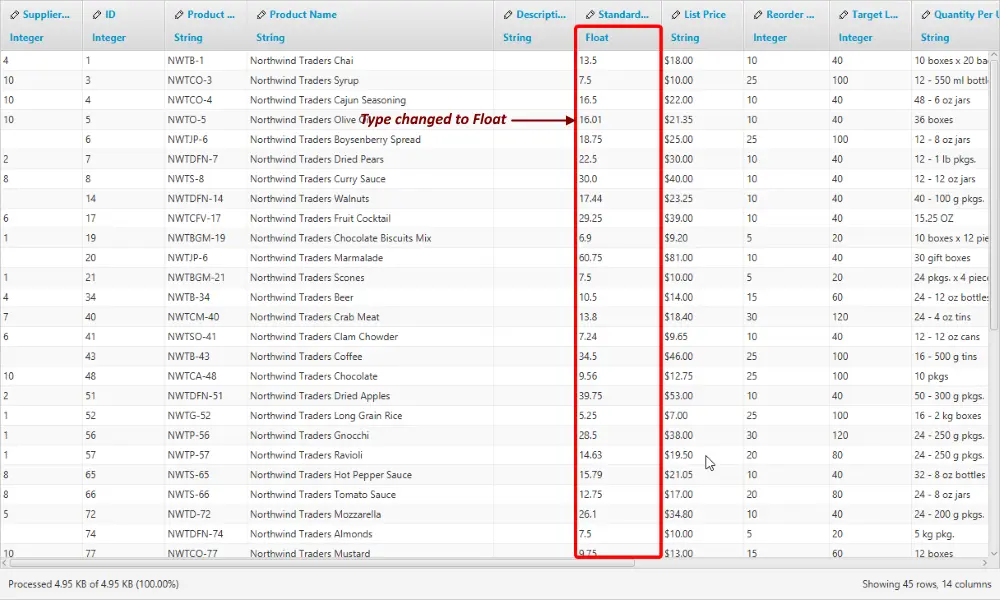
3. Type is now Float with currency sign stripped.
Now you can repeat the same for any other columns.
Parsing Dates
Let us now look at another example where we need to parse dates in a specific format. Normally, date fields in well known formats (such as ISO 8601) are also automatically parsed. But when your file contains a date in a less used format, you need to adjust the type specifically.
1. Using dates with two digit years without a care
In the following image, we have two columns which use a two-digit year in the format MM/dd/yy with possibly one digit only for the month and day.
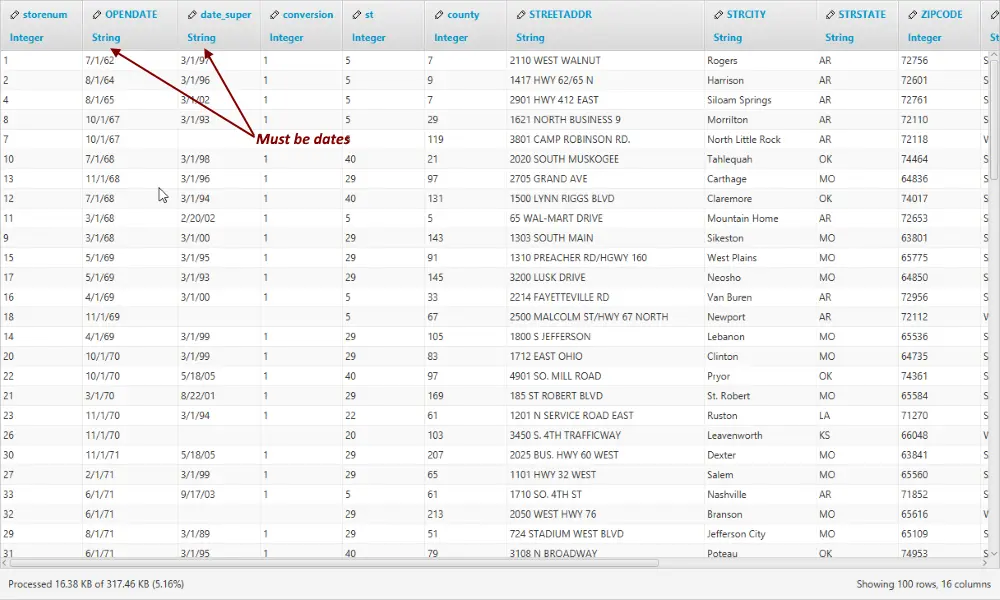
2. Adjust type to DateTime
As before, change the type from String to DateTime and select the date format that matches the one in the column. The dialog also includes setting for specifying the time format, but since the column we are looking at does not contain time, we have no need for it. Click Apply after making adjustments.
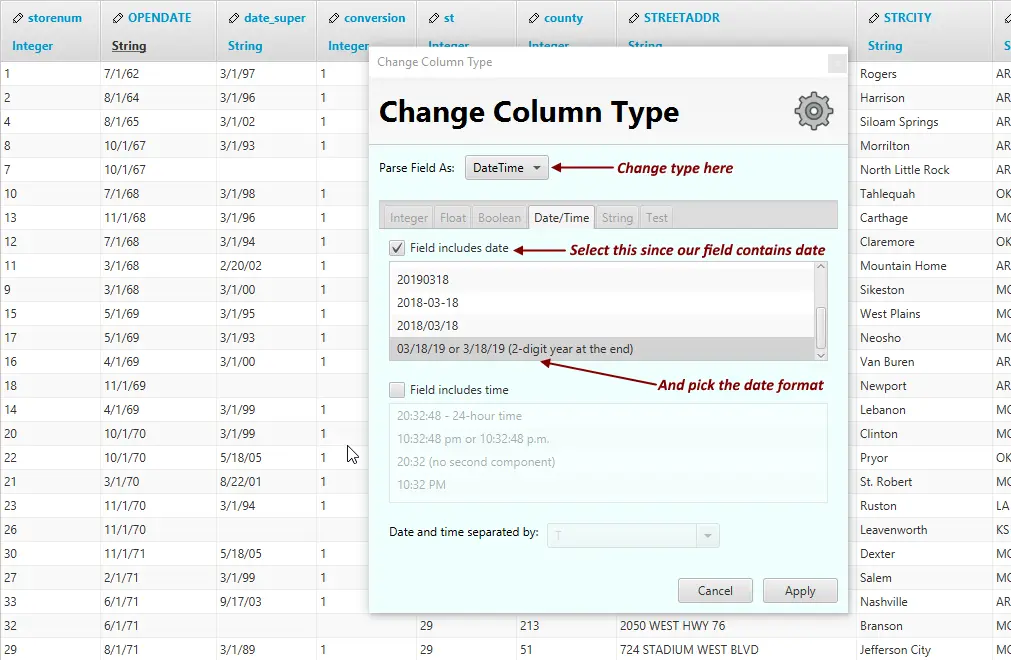
3. Updated column type to Date
We have now changed the type of the column from String to Date. Repeat for as many columns as necessary.
Conclusion
When parsing CSV getting the correct types for the fields can be a bit of a hassle. It helps to use an automatic type identification system which uses the first few rows for identifying types.
Import Large CSV without memory issues
-
Automatic type detection included No more string types everywhere.
-
Includes an embedded database Argon includes a recent version of Elasticsearch, so when you download and install it, the database is ready.
-
Easy for non-techies Intuitive UI with drag and drop. No coding required.